Code Mode: Khi Cloudflare Dạy AI 'Viết Code' Thay Vì 'Gọi Tool' — Và Bài Học Cho Tương Lai Documentation
Cloudflare vừa giải quyết một vấn đề mà hầu hết developer chưa nhìn thấy: AI agent đang 'ngạt thở' vì quá nhiều tool. Cách họ fix? Bỏ tool đi, cho AI viết code. Và cách tiếp cận này đang thay đổi hoàn toàn cách chúng ta nghĩ về documentation.
Code Mode: Khi Cloudflare Dạy AI “Viết Code” Thay Vì “Gọi Tool” — Và Bài Học Cho Tương Lai Documentation
Bạn có bao giờ để ý là… khi bạn nhờ AI agent làm một việc đơn giản — như “cấu hình DNS cho domain mới” — nó phải đọc hàng trăm nghìn token mô tả tool trước khi làm bất cứ điều gì?
Này không phải bug :D, đó là feature: cách MCP hoạt động. Và Cloudflare vừa phán: cách này sai từ đầu.
Trong hai bài blog gần đây — Code Mode: the better way to use MCP (09/2025) và Code Mode: give agents an entire API in 1,000 tokens (02/2026) — đội ngũ Cloudflare trình bày một cách tiếp cận khiến mình phải đọc lại hai lần.
Insight cốt lõi: LLM rất giỏi viết code — vì nó đã được train (huấn luyện) trên hàng triệu project mã nguồn mở. Nhưng LLM rất kém trong việc “gọi tool” — vì nó chỉ được fine-tune (tinh chỉnh thêm) trên một bộ dữ liệu nhân tạo nhỏ xíu.
Vậy thì… tại sao chúng ta cứ bắt AI gọi tool?
TL;DR
Cho người kỹ thuật: Cloudflare chuyển 2,500 API endpoints → 2 tools (search + execute). LLM viết JavaScript code chạy trong V8 isolate sandbox. Token sử dụng giảm 99.9% — từ 1.17M xuống ~1,000.
Cho người không kỹ thuật: Thay vì đưa cho AI một cuốn sổ tay 500 trang mỗi lần hỏi, Cloudflare cho AI khả năng tự tra cứu và viết lệnh. Kết quả: nhanh hơn, rẻ hơn, và chính xác hơn.
Vấn đề: AI agent đang “ngạt thở”
Để hiểu tại sao Code Mode quan trọng, bạn cần hiểu cái tình cảnh mà AI agent đang mắc kẹt.
Context window (bộ nhớ ngắn hạn) — căn phòng nhỏ, quá nhiều đồ
Mỗi khi AI agent kết nối một MCP server, nó phải load toàn bộ schema (bản mô tả cấu trúc) của tất cả tool vào context window — tức bộ nhớ làm việc ngắn hạn của nó. Hãy tưởng tượng context window như một căn phòng làm việc. Mỗi tool là một cuốn sổ tay hướng dẫn mà AI phải giữ trên bàn — dù có dùng hay không.
Tính đơn giản:
100 MCP tools × 1,000 tokens/schema = 100,000 tokens
+ 10 kết quả trung gian × 2,000 tokens = 20,000 tokens
+ suy luận = 50,000 tokens
─────────────────────────────────────────
TỔNG: ~170,000 tokens → bắt đầu hallucinate (ảo giác, bịa ra thông tin), chi phí bùng nổVà đây mới là 100 tool. Cloudflare API có 2,500 endpoints. Nếu load hết?
1.17 triệu tokens. Lớn hơn context window của mọi foundation model hiện tại. Không model nào đọc nổi — kể cả những model flex “1M context”.
Nói nôm na: Bạn bắt AI đọc một cuốn sách 3,000 trang trước khi trả lời câu hỏi “domain của tao đang bị DDoS, làm gì bây giờ?”. Nó quên mất câu hỏi trước khi đọc xong. Kiểu bạn mở Stack Overflow tìm lỗi, 30 phút sau đang đọc bài về cách nuôi mèo.
Ba vấn đề cốt lõi
-
Static Discovery (khám phá cứng nhắc): AI nhìn thấy danh sách tool cố định từ đầu. Khi có endpoint (điểm truy cập API) mới, phải load lại toàn bộ.
-
Không có orchestration (điều phối nhiều bước): Khi cần lặp, phân trang, hoặc nối nhiều lệnh lại với nhau, AI phải quay lại LLM mỗi bước → re-prompt (hỏi lại) liên tục → tốn token + chậm.
-
Tool calling không tự nhiên: JSON schema cho tool call là format nhân tạo. LLM phải output (xuất ra) những token đặc biệt mà nó chưa từng thấy “trong tự nhiên” — kiểu bạn bắt nó nói một ngôn ngữ lạ mà chỉ được học qua vài bài tập mẫu.
Cái insight thật sự khiến mình dừng lại
Đây là đoạn từ bài blog của Kenton Varda (co-creator Protocol Buffers, người xây dựng Cloudflare Workers architecture):
“Making an LLM perform tasks with tool calling is like putting Shakespeare through a month-long class in Mandarin and then asking him to write a play in it. It’s just not going to be his best work.”
Đọc lại câu này thêm lần nữa đi, mình đợi.
LLM đã “đọc” hàng triệu open-source project. Nó biết cách viết TypeScript, JavaScript, Python. Nó biết convention (quy ước viết code). Nó biết pattern (khuôn mẫu). Nó đã thấy /zones/{id}/rulesets hàng triệu lần trong code thật.
Nhưng tool calling? Đó là format nhân tạo — phải fine-tune riêng — với bộ dữ liệu huấn luyện nhỏ xíu, do developer tự tạo.
Nói cách khác: chúng ta đang bắt Shakespeare viết kịch bằng ngôn ngữ mà ông ấy mới học 1 tháng.
Câu hỏi này đang đặt sai vấn đề từ đầu. Thay vì hỏi “làm sao cho AI gọi tool tốt hơn?”, câu hỏi đúng phải là “tại sao phải bắt AI gọi tool khi nó viết code giỏi hơn 100 lần?”
Code Mode: giải pháp — đừng gọi tool, hãy viết code
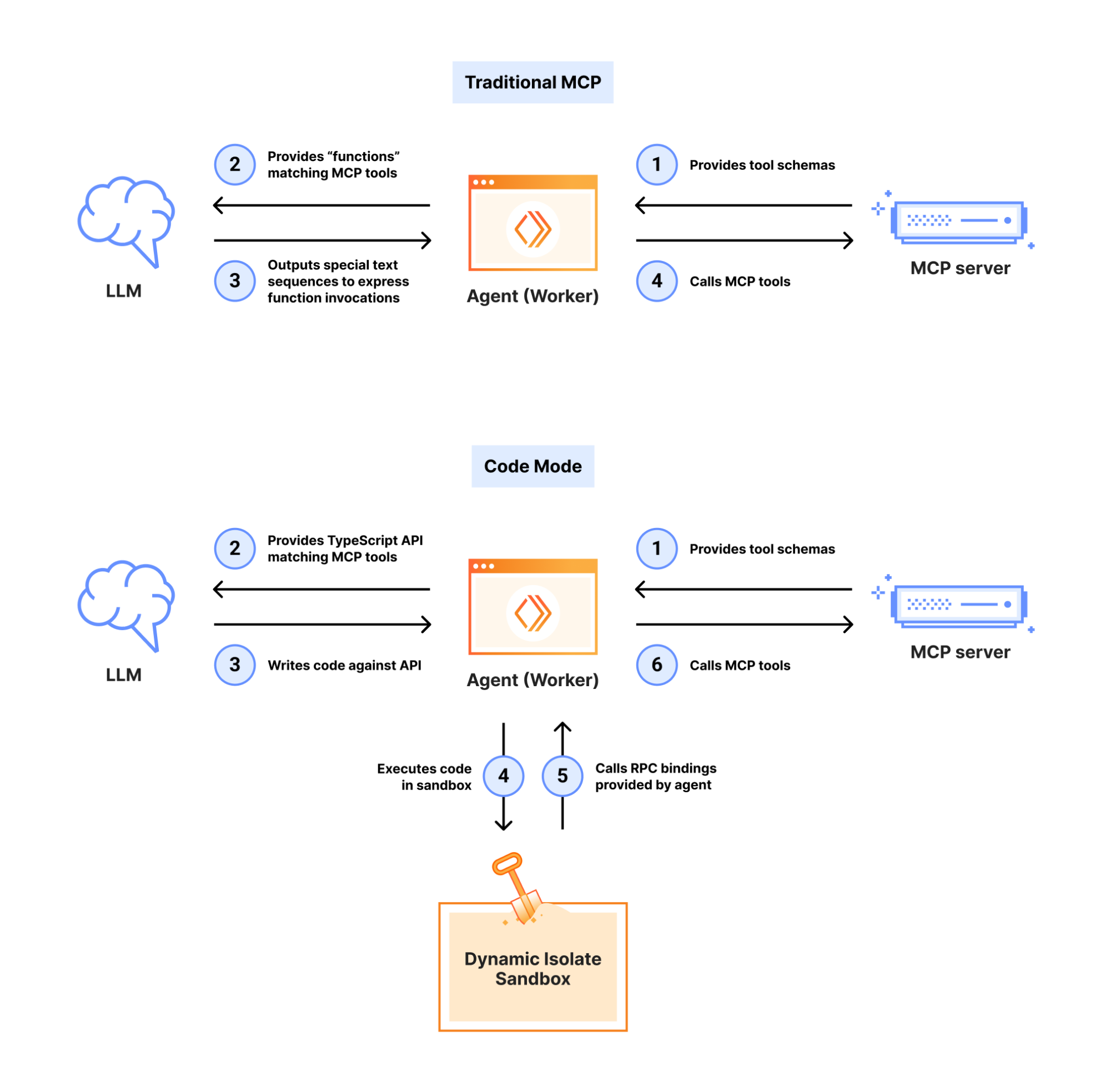
Cloudflare triển khai Code Mode theo 2 hướng. Cả hai đều dựa trên cùng một nguyên lý: chuyển MCP tools thành TypeScript API, để LLM viết code thay vì gọi tool.
Hướng 1: client-side Code Mode (Cloudflare Agents SDK)
Ý tưởng: Phía client wrap tất cả MCP tools thành một SDK kiểu TypeScript. LLM chỉ thấy 1 tool duy nhất: execute_code({code}).
Trước (MCP truyền thống):
AI thấy 200 tools → chọn 1 → gọi → đọc kết quả → chọn tool tiếp → gọi → ...
Token: 200,000+
Sau (Code Mode):
AI thấy 1 tool: execute_code
AI viết: "const u = await tools.getUser({id: 123});
const orders = await tools.listOrders(u.id);
console.log(orders);"
Token: ~2,500 (cố định)Điểm then chốt: AI viết một đoạn code hoàn chỉnh xử lý toàn bộ workflow — thay vì ping-pong giữa LLM và tool server suốt 10 turn. Ai từng debug một chuỗi tool call 8 bước thì hiểu cái đau này.
Hướng 2: server-side Code Mode (Cloudflare MCP Server)
Đây là phiên bản mạnh hơn — và thú vị hơn.
MCP server chỉ export 2 tools: search() và execute(). Cả hai đều nhận input là JavaScript code.
[
{
"name": "search",
"description": "Search the Cloudflare OpenAPI spec.",
"inputSchema": {
"properties": {
"code": {
"type": "string",
"description": "JavaScript async arrow function to search the OpenAPI spec"
}
}
}
},
{
"name": "execute",
"description": "Execute JavaScript code against the Cloudflare API.",
"inputSchema": {
"properties": {
"code": {
"type": "string",
"description": "JavaScript async arrow function to execute"
}
}
}
}
]2 tools. ~1,000 tokens. Bao phủ 2,500+ endpoints. Đọc lại một lần nữa cho chắc — hai tools, hai ngàn rưỡi endpoints.
Và phần hay nhất: khi API thêm endpoint mới → không cần thêm tool mới → search() sẽ tự discover (tự phát hiện ra). Không ai phải thức đêm viết thêm MCP tool definition.
Ví dụ thực tế: bảo vệ origin khỏi DDoS
User nói: “Bảo vệ origin của tao khỏi DDoS.”
Bước 1: Agent gọi search() — viết JavaScript để tìm endpoint liên quan:
async () => {
const results = [];
for (const [path, methods] of Object.entries(spec.paths)) {
if (path.includes('/zones/') &&
(path.includes('firewall/waf') || path.includes('rulesets'))) {
for (const [method, op] of Object.entries(methods)) {
results.push({ method: method.toUpperCase(), path, summary: op.summary });
}
}
}
return results;
}Kết quả: 10 endpoints phù hợp — từ 2,500 endpoints, không cần nạp spec vào context.
Bước 2: Agent gọi search() lần nữa để kiểm tra schema chi tiết — tìm các phase available:
async () => {
const op = spec.paths['/zones/{zone_id}/rulesets']?.get;
const props = op?.responses?.['200']?.content?.['application/json']
?.schema?.allOf?.[1]?.properties?.result?.items?.allOf?.[1]?.properties;
return { phases: props?.phase?.enum };
}Kết quả: ddos_l7, http_request_firewall_managed — chính xác những gì cần.
Bước 3: Agent gọi execute() — viết code thực thi API:
async () => {
const response = await cloudflare.request({
method: "GET",
path: `/zones/${zoneId}/rulesets`
});
return response.result.map(rs => ({
name: rs.name, phase: rs.phase, kind: rs.kind
}));
}4 tool calls tổng cộng. Từ “bảo vệ DDoS” → khám phá API → kiểm tra schema → thực thi. Toàn bộ trong ~1,000 tokens context. Tổ tiên MCP truyền thống cần bao nhiêu turn cho workflow này? Mình không muốn tính.
Vì sao Code Mode “win”? — phân tích qua 3 lăng kính
Lăng kính 1: So what? — tiết kiệm 99.9% token, rồi sao?
Tiết kiệm 99.9% token nghe giống slide marketing của sales team. Nhưng cái hay thật sự nằm ở chỗ khác:
Khi context không bị chiếm bởi tool schema → AI có nhiều không gian hơn để suy nghĩ.
Bạn biết cái cảm giác khi mở 47 tab Chrome và máy bắt đầu quay quạt? Context window của LLM cũng y hệt. Khi 80% context bị chiếm bởi schema mà AI không cần đọc → nó còn rất ít “bandwidth” (dung lượng xử lý) để reasoning (suy luận).
Code Mode giải phóng bandwidth đó. Giống như bạn đóng 45 tab — đột nhiên mọi thứ mượt hẳn.
| Metric | MCP Truyền Thống | Code Mode |
|---|---|---|
| Tokens (2,500 endpoints) | 1,170,000 | ~1,000 |
| Scaling (mở rộng) khi thêm endpoint | Tuyến tính (thêm endpoint = thêm token) | Cố định |
| Orchestration (điều phối) | Re-prompt mỗi bước | Code tự chain (tự nối lệnh) |
| Discovery (khám phá) | Static list, load hết | Dynamic search (tìm kiếm linh hoạt) |
Lăng kính 2: obsolete wisdom (kiến thức lỗi thời) — “best practice” nào đang sai?
Đây là phần mình thấy hay nhất.
“Best practice” hiện tại: Khi xây MCP server, hãy tinh giản tool — ít parameter, mô tả đơn giản, chia nhỏ operation. Mình cũng từng làm vậy, và chắc bạn cũng thế.
Cloudflare nói thẳng: best practice này đang workaround (đi đường vòng để tránh) một giới hạn mà lẽ ra không cần tồn tại.
MCP server designer đang “dumb it down” API vì sợ LLM không xử lý được tool phức tạp. Nhưng nếu chuyển sang code? LLM handle full, complex API ngon lành — cùng một model, chỉ khác format input.
Obsolete wisdom: “Mỗi MCP tool nên đơn giản, làm 1 việc duy nhất.” New reality: “Cho AI 2 primitives (hai thao tác cơ bản nhất: search + execute) và nó tự compose (ghép lại, tổ hợp) bất cứ workflow nào.”
Lăng kính 3: irreversibility (không thể đảo ngược) — cái gì không thể un-do?
Khi community adopt (áp dụng) Code Mode rộng rãi, cách viết documentation sẽ thay đổi vĩnh viễn. Đây là thay đổi ở tầng nền tảng — documentation đang ở inflection point (điểm ngoặt), và nó sẽ không quay lại.
Documentation revolution: cái “core” mà ít người nhìn thấy
Đây là phần mà Cloudflare hint nhưng không triển khai sâu — và mình nghĩ đây mới là lesson đáng giá nhất trong toàn bộ câu chuyện Code Mode.
Cách cũ: Documentation cho người đọc
Documentation truyền thống:
1. Mô tả verbose bằng prose (nhìn docs của Stripe, AWS)
2. Examples cụ thể cho từng use case
3. RAG pipeline fetch → chunk → feed vào LLM
4. Kết quả: hallucinations, outdated info, context bloatCách mới: Documentation cho máy đọc (Schema-First)
Cloudflare chứng minh rằng 2 primitives + TypeScript type definitions đủ để LLM hiểu 2,500 endpoints.
declare const cloudflare: {
/** Paths from OpenAPI spec. Pagination: result_info.cursor */
request: (opts: {
method?: 'GET' | 'POST' | 'PATCH';
path: string; // e.g. '/zones/{zone_id}/rulesets'
body?: object;
}) => Promise<{ result: any[]; result_info: { cursor?: string } }>;
};~500 tokens. LLM đọc xong biết:
path: string→ đây là REST endpointmethod?: 'GET' | 'POST'→ HTTP verbs availableresult_info.cursor→ có pagination- JSDoc
/** Paths from OpenAPI spec */→ biết tra cứu ở đâu
Và nó viết đúng code ngay lần đầu:
await cloudflare.request({
method: 'PATCH',
path: `/zones/${zoneId}/rulesets/${id}`,
body: { sensitivity: 'high' }
})Mô hình documentation mới
Perfect LLM Docs:
1. TypeScript primitives (~500 tokens) — type contract
2. OpenAPI/JSON spec (searchable, KHÔNG load vào context)
3. Inline JSDoc hints — context ngắn gọn
4. Zero baked-in examples — LLM tự composeBạn thấy đó… Chúng ta đang thêm một audience mới cho documentation: máy. Viết docs cho developer đọc vẫn cần, nhưng giờ cần viết thêm schema cho LLM program.
Nghĩ về nó như README.md vs. types.d.ts — cùng mô tả một thứ, nhưng cho hai audience khác nhau. Và “Machine Docs” không phải bản tóm tắt của Human Docs — nó là format riêng, với standard riêng.
Sandbox: tại sao V8 isolates là đáp án đúng
Bạn có thể nghĩ: “OK cho AI viết code thì security thế nào?” Câu hỏi rất đúng. Và Cloudflare có một lợi thế mà ít platform nào có: V8 isolates.
Container vs. isolate
Hầu hết giải pháp sandbox hiện tại dùng container (Docker). Mỗi lần AI tạo code, bạn spin up một container, chạy code, rồi destroy. Nghe quen? Đúng rồi, nó chậm và tốn tài nguyên y như bạn nghĩ.
Cloudflare dùng V8 isolates thay container:
| Container | V8 Isolate | |
|---|---|---|
| Startup | Hàng giây | Vài millisecond |
| Memory | Hàng trăm MB | Vài MB |
| Cost | Cao (vì nặng) | Rẻ hơn nhiều |
| Tạo fresh | Phải pool/reuse | Tạo mới mỗi lần, dùng xong bỏ |
Mỗi đoạn code AI viết → tạo 1 isolate mới → chạy → destroy. Kiểu ly giấy — dùng xong bỏ, không cần rửa. Nhanh đến mức overhead gần như bằng 0.
Security model: bindings thay vì API keys
Phần này mình thích nhất — vì nó giải quyết một nỗi sợ rất thực.
Cách truyền thống: sandbox có network access → gọi API bằng API key → rủi ro leak key qua prompt injection.
Cách Cloudflare: Sandbox không có network access. Không fetch(). Không connect().
Thay vào đó, sandbox nhận bindings (kết nối trực tiếp) — live objects cung cấp interface đã-authorize (được cấp quyền) sẵn đến MCP servers cụ thể.
Truyền thống:
Code → fetch("https://api.cloudflare.com", {headers: {Authorization: API_KEY}})
→ Rủi ro: AI có thể leak key
Code Mode:
Code → cloudflare.request({method: 'GET', path: '/zones'})
→ Binding tự inject auth ở tầng supervisor
→ Code KHÔNG BAO GIỜ thấy keyAI không thể viết code leak API key vì nó không biết key tồn tại. Giống kiểu: bạn không thể đánh mất chìa khóa mà bạn chưa từng cầm.
Đây là một bài học thú vị về nguyên lý system design (thiết kế hệ thống), không chỉ riêng cho security. Tách “cái gì” (gọi API) ra khỏi “như thế nào” (auth — xác thực, networking — kết nối mạng) — và cả một lớp vấn đề tự biến mất.
So sánh với các approach khác
Cloudflare không phải team duy nhất nhận ra vấn đề — nhưng cách họ so sánh các approach rất rõ ràng:
1. CLI-based (OpenClaw, Moltworker)
Chuyển MCP tools thành CLI commands. AI explore bằng cách gõ lệnh.
- ✅ Self-documenting (tự mô tả cách dùng)
- ❌ Cần shell → attack surface (bề mặt tấn công) lớn
- ❌ Không phải environment nào cũng có shell
2. Dynamic Tool Search (Claude Code)
Search subset của tools phù hợp task hiện tại, chỉ load subset đó.
- ✅ Giảm context
- ❌ Vẫn phải maintain search function riêng
- ❌ Mỗi matched tool vẫn tốn token
3. Client-Side Code Mode (Goose, Claude SDK)
Agent viết TypeScript chạy trong sandbox trên client.
- ✅ Tương tự server-side
- ❌ Yêu cầu agent phải có sandbox access
- ❌ Phức tạp hơn cho agent developer
4. Server-Side Code Mode (Cloudflare) ← Winner
2 tools (search + execute), sandbox trên server.
- ✅ Token cố định bất kể API size
- ✅ Agent không cần modify gì
- ✅ Progressive discovery (tự khám phá dần) built-in
- ✅ Isolate sandbox an toàn
Pattern chung: mọi approach đều cố giảm token. Nhưng Code Mode server-side là approach duy nhất giữ token cố định bất kể scale. O(1) thay vì O(n) — nếu bạn thích complexity notation.
Bài học cho bạn: áp dụng Code Mode thinking
Nếu bạn là developer xây MCP server
Hành động ngay:
- Thử Cloudflare MCP Server — config 2 dòng trong MCP client:
{
"mcpServers": {
"cloudflare-api": {
"url": "https://mcp.cloudflare.com/mcp"
}
}
}-
Áp dụng pattern
search + executecho MCP server của riêng bạn:- Chuyển OpenAPI spec thành searchable object
- Expose 2 tools thay vì N tools
- Sandbox code bằng V8 isolates (hoặc ít nhất Node
vmmodule cho prototype — đừngeval()trần, xin bạn 🙏)
-
Viết Machine Docs bên cạnh Human Docs:
- TypeScript type definitions
- JSDoc inline hints
- Searchable spec (không bake vào context)
Nếu bạn là technical writer
Documentation đang rẽ nhánh. Bạn cần viết cho 2 audience:
| Audience | Format | Mục đích |
|---|---|---|
| Human | Prose, tutorial, getting started | Teach concepts |
| Machine (LLM) | TypeScript contracts, JSDoc, searchable spec | Enable programmatic access |
Tip: Bắt đầu bằng cách viết TypeScript interface cho API endpoint. Nếu bạn viết summary trong JSDoc mà LLM vẫn gọi sai → bạn cần viết rõ hơn. Test với AI như test với junior dev — nếu nó hiểu nhầm, lỗi ở docs.
Nếu bạn là AI/vibe coder
Code Mode là ví dụ hoàn hảo cho tư duy system design:
- Đừng đổ thêm tools vào AI → AI sẽ chậm + sai (giống bạn cài 47 VS Code extension rồi thắc mắc sao lag)
- Hãy cho AI ít primitives + khả năng compose → AI sẽ tự tìm cách
- Logic đi trước, cú pháp đi sau — design API surface trước, rồi mới implement
Góc nhìn xa hơn: MCP Server Portals
Cloudflare đã hint hướng tiếp theo: MCP Server Portals.
Vấn đề mới: Code Mode giải quyết context cho 1 API. Nhưng agent thật sự cần kết nối nhiều service — Cloudflare + GitHub + database + docs server. Mỗi MCP server thêm context pressure.
Giải pháp tương lai: Portals — compose (ghép) nhiều MCP servers sau 1 gateway (cổng chung), unified auth (xác thực tập trung), tất cả chạy Code Mode với progressive discovery.
Hãy tưởng tượng: 1 agent, 2 tools (search + execute), truy cập Cloudflare + GitHub + Supabase + nội bộ — vẫn chỉ 1,000 tokens.
Chúng ta chưa ở đó — nhưng hướng thì đã khá rõ ràng.
Key takeaways
1. LLM là programmer, hãy để nó viết code
Ngừng bắt AI gọi hàm bằng format nhân tạo. Cho nó viết code — nó giỏi cái này vì nó đã “đọc” internet.
2. Token cố định = scaling thật sự
search + execute = ~1,000 tokens bất kể 100 hay 100,000 endpoints. Đây là khác biệt giữa “giảm token” và “giải quyết vấn đề token từ gốc.”
3. Documentation đang rẽ nhánh
Human Docs (prose, tiếng Việt, metaphor, tutorials) vẫn cần thiết. Bên cạnh đó, Machine Docs (TypeScript contracts + searchable specs) sẽ trở thành standard song song. Bạn cần viết cả hai.
4. Security bắt đầu từ abstraction (giấu đi cái phức tạp)
V8 isolates + bindings > container + API keys. Abstract đi cái nguy hiểm (network, keys), chỉ expose (để lộ) cái an toàn (typed interface — giao diện có kiểu dữ liệu rõ ràng). Một bài học thú vị về system design — không chỉ riêng cho security.
5. Compose (ghép lại), đừng accumulate (chồng thêm)
“Best practice” cũ: thêm endpoint → thêm tool → chồng thêm mãi. Code Mode: thêm endpoint → search() tự discover → hệ thống tự mở rộng mà không “nặng” thêm.
Kết
Mình không hay viết về từng tính năng của từng platform — nhưng Code Mode khiến mình tò mò đủ để ngồi đọc kỹ hai bài blog và viết hẳn bài dài thế này. Vì nó không chỉ là chuyện optimize token — nó cho thấy hướng đi rõ ràng:
- AI agents sẽ viết code nhiều hơn, gọi tool ít hơn.
- Documentation sẽ phục vụ máy song song với người.
- Sandbox sẽ chuyển từ container sang isolate.
- API surface design (thiết kế bề mặt API) sẽ tối ưu cho LLM composition (khả năng tổ hợp của LLM).
Cloudflare đang ship production với approach này. Bạn có thể thử ngay hôm nay — chỉ cần 2 dòng config. Không cần đợi, không cần waitlist.
Câu hỏi bây giờ là: “Nếu LLM viết code giỏi hơn gọi tool — thì bao nhiêu phần trong hệ thống AI hiện tại của bạn đang chọn sai approach?”
Bài viết dựa trên Code Mode: the better way to use MCP (Kenton Varda & Sunil Pai, 09/2025) và Code Mode: give agents an entire API in 1,000 tokens (Matt Carey, 02/2026).