Code mode đừng bắt AI gọi tool mãi
Khi MCP server phình ra hàng chục tool, agent dễ chậm và lạc. Code Mode trong VibeWork chọn hướng ngược lại: chỉ search, execute, rồi để AI viết JavaScript an toàn trong sandbox.
Code mode đừng bắt AI gọi tool mãi
Một agent có quá nhiều công cụ trước mặt thường không mạnh hơn, mà dễ ngộp hơn. Agent (tác tử AI, phần mềm có thể tự chọn bước và dùng công cụ để làm việc) bây giờ có thể nối vào nhiều MCP server cùng lúc, mỗi server lại mở ra vài chục đến vài trăm tool. Nhìn riêng từng tool thì hợp lý, nhưng đặt tất cả vào cùng một context window (cửa sổ ngữ cảnh, vùng trí nhớ ngắn hạn model có thể đọc trong một lượt), ta giống như đặt một trăm quyển hướng dẫn lên chiếc bàn nhỏ rồi yêu cầu một người vừa đọc, vừa nhớ, vừa làm chính xác. Vấn đề không chỉ là bàn chật; vấn đề là công việc thật sự cần làm bị vùi dưới chính các hướng dẫn để làm việc.
VibeWork chọn một hướng khác cho hệ thống nội bộ của mình. Thay vì đưa cho AI 50 hay 100 tool, VibeWork đưa hai tool: search và execute. Phần còn lại để AI viết một đoạn JavaScript nhỏ và chạy nó trong sandbox (hộp cát bảo vệ, môi trường giới hạn để code không chạm vào thứ không được phép). Nghe có vẻ lạ nếu quen với cách thiết kế MCP truyền thống, nhưng càng nhìn vào công việc nội bộ càng thấy hợp lý: nhiều thao tác không phải một cú click đơn lẻ, mà là logic nối nhiều bước.
MCP đang phình ra quá nhanh
MCP (Model Context Protocol, giao thức kết nối ngữ cảnh model) giúp harness (bộ khung điều khiển AI) nối LLM (large language model, mô hình ngôn ngữ lớn) với app và dữ liệu bên ngoài. Cách triển khai phổ biến là mỗi hành động thành một tool riêng, mỗi tool có schema (mô tả cấu trúc input và output) riêng, và mỗi khi agent kết nối, model phải thấy các schema đó để biết cách gọi. Với một hệ thống nhỏ, chuyện này ổn. Với một hệ thống nội bộ nghiêm túc có CRM, HRM, task, nhân sự, approval và reporting, bề mặt tool phình ra rất nhanh.

Cái bẫy của schema giàu hơn
Mỗi schema đều có lý do tồn tại. Nếu mô tả quá mỏng, model dễ gọi sai. Nếu mô tả đủ giàu, nó tốn token (đơn vị văn bản AI dùng để tính và xử lý ngôn ngữ). Cái bẫy nằm ở đó: để AI dùng tool đúng hơn, mình viết schema tốt hơn; nhưng chính schema tốt hơn làm context nặng hơn. Khi người dùng chỉ hỏi “tuần này có deal sales nào sắp trễ follow-up không?”, agent vẫn phải mang theo hướng dẫn của HR, task store, contact directory, reporting và permission. Nó chưa làm gì đã đọc quá nhiều thứ có thể không liên quan.
Hệ quả thực tế là agent chậm hơn, chọn tool nhầm nhiều hơn và đôi khi tưởng tượng đường đi thay vì thao tác chắc chắn. Đây không nhất thiết là lỗi model yếu. LLM được huấn luyện trên lượng code khổng lồ, từ JavaScript, TypeScript, Python tới API client, vòng lặp, filter, map và xử lý dữ liệu. Tool calling thì nhân tạo hơn: model phải phát ra đúng format đặc biệt, đúng tên tool, đúng schema, đúng bước, rồi chờ kết quả để quyết định bước kế tiếp. Nó làm được, nhưng đó không phải ngôn ngữ tự nhiên nhất của nó.
Pattern Code Mode của Cloudflare
Cloudflare đã popularize pattern Code Mode theo đúng hướng này. Thay vì mở hàng nghìn endpoint thành hàng nghìn tool, ta đưa cho agent một bề mặt nhỏ hơn để viết code dựa vào. So sánh nhẹ thì gọi tool giống bắt một người viết giỏi điền rất nhiều mẫu hành chính: họ có thể làm, nhưng năng lực tốt nhất của họ không nằm ở việc chọn đúng ô biểu mẫu qua nhiều vòng. Viết code lại gần với vùng model đã luyện nhiều hơn, nhất là khi workflow có điều kiện, nhóm dữ liệu, vòng lặp và bước phụ thuộc nhau.
Cách cũ vs cách mới
Trong cách cũ, một workflow như “tìm task quá hạn của team sales, nhóm theo owner, tạo note follow-up” sẽ thành nhiều lượt ping-pong. Agent gọi tool lấy task, model đọc kết quả, agent gọi tool lọc user, model đọc tiếp, agent gọi tool tạo note, rồi lặp qua từng owner. Mỗi lượt có latency, tốn token và thêm một cơ hội để model trôi khỏi ý định ban đầu. Đến bước thứ bảy, cảm giác token rơi trên sàn không phải ẩn dụ quá xa.
Với Code Mode, agent viết một đoạn JavaScript nhỏ: list tasks, filter overdue, group by owner, create follow-up notes, return summary. Đoạn đó chạy một lần trong sandbox, nơi các namespace như vibework đã được cài sẵn. Model nghĩ một lần, viết kế hoạch một lần, chạy một lần, rồi quan sát kết quả. Với công việc có map, filter, reduce, grouping và dependent steps, đây là cách diễn đạt tự nhiên hơn nhiều so với kéo model qua từng tool call nhỏ.
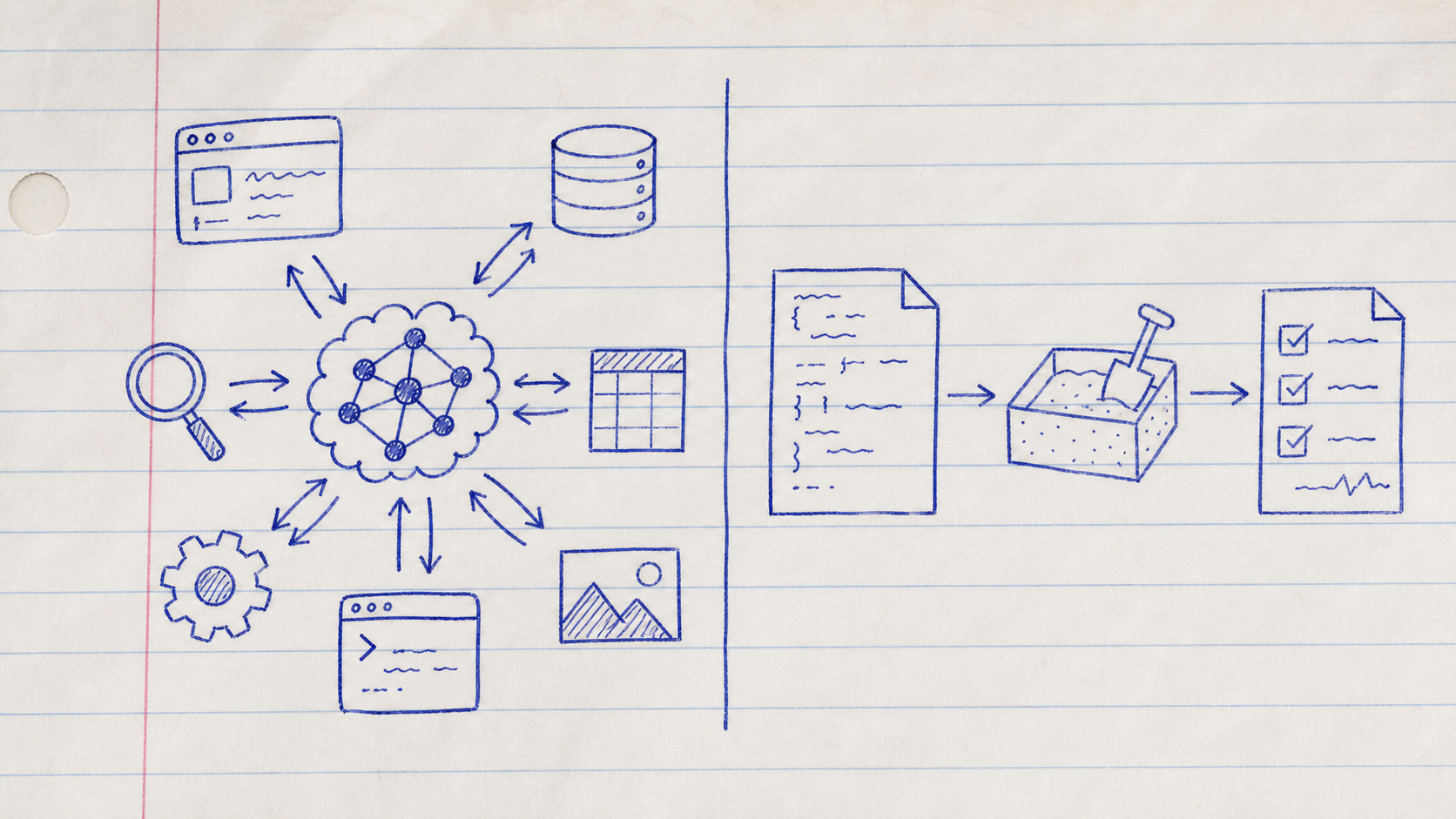
VibeWork build gì bên trong
VibeWork là CRM và HRM nội bộ được thiết kế agent-first, nghĩa là AI là một người dùng hạng nhất trong hệ thống, không phải phụ kiện gắn thêm sau cùng. Nếu đi theo đường MCP thông thường, mỗi API trong VibeWork có thể thành một tool. Nhưng bề mặt đó sẽ lớn mãi khi sản phẩm lớn lên. Vì vậy Code Mode MCP server của VibeWork chỉ giữ hai tool công khai.
Tool đầu tiên là search({ query }). Agent hỏi bằng ngôn ngữ gần với việc cần làm, ví dụ “task overdue sales follow-up”, rồi nhận lại các function liên quan với mô tả và schema kiểu TypeScript. Nó không cần thấy toàn bộ vũ trụ VibeWork ngay từ đầu. Nó chỉ tìm những gì cần cho việc trước mặt. Đây là khác biệt giữa mang cả nhà kho trên lưng và biết đường tới nhà kho khi cần lấy đồ.
Tool thứ hai là execute({ code }). Agent gửi một đoạn JavaScript ngắn; server tạo một sandbox mới, cài vào đó các function được phép như vibework.list_tasks hay vibework.create_note, rồi chạy code. Mỗi lần execute là một runtime sạch, không tái sử dụng trạng thái cũ. Điều này quan trọng trong hệ thống nhiều tenant và nhiều scope, vì một lần chạy không nên để lại dữ liệu hay biến môi trường có thể rò sang lần sau.
Vì sao cách này thông minh hơn
Lợi ích đầu tiên là rẻ hơn về context. Model chỉ cần biết hai tool cố định, còn danh sách function thật nằm sau search. Khi thêm function mới, mỗi cuộc hội thoại không tự động phải mang thêm một schema nữa. Registry có thể lớn lên mà bề mặt agent cần giữ trong đầu không lớn cùng tốc độ. Với nội bộ công ty, nơi mỗi tuần có thể thêm báo cáo, approval, automation và field mới, đây là một khác biệt kiến trúc chứ không chỉ là mẹo tiết kiệm.
Lợi ích thứ hai là nhanh hơn và hợp với thế mạnh của LLM. Gọi tool truyền thống giống một cuộc họp mà mỗi câu đều cần duyệt: nói một câu, chờ phản hồi, đọc biên bản, rồi nói câu tiếp. Code Mode gom phần orchestration vào một mảnh code. Agent có thể biểu diễn ý định bằng cấu trúc rõ ràng: biến, điều kiện, vòng lặp, function call, return. Những thứ này model đã thấy hàng triệu lần trong dữ liệu huấn luyện, nên nó thường ổn định hơn khi workflow có logic.

Lợi ích thứ ba là khả năng lớn lên mà không làm agent ngộp. Một hệ thống nội bộ không đứng yên. Hôm nay có list task, mai có approval flow, tuần sau có policy check, tháng sau có reporting mới. Nếu mỗi thứ thành tool, MCP server trở thành một menu dài không hồi kết. Với Code Mode, function mới được đăng ký vào registry, search() tìm ra nó, execute() chạy nó, còn public surface vẫn là hai tool. Hệ thống lớn hơn, nhưng chiếc bàn làm việc của agent không phải nở ra theo cùng tỷ lệ.
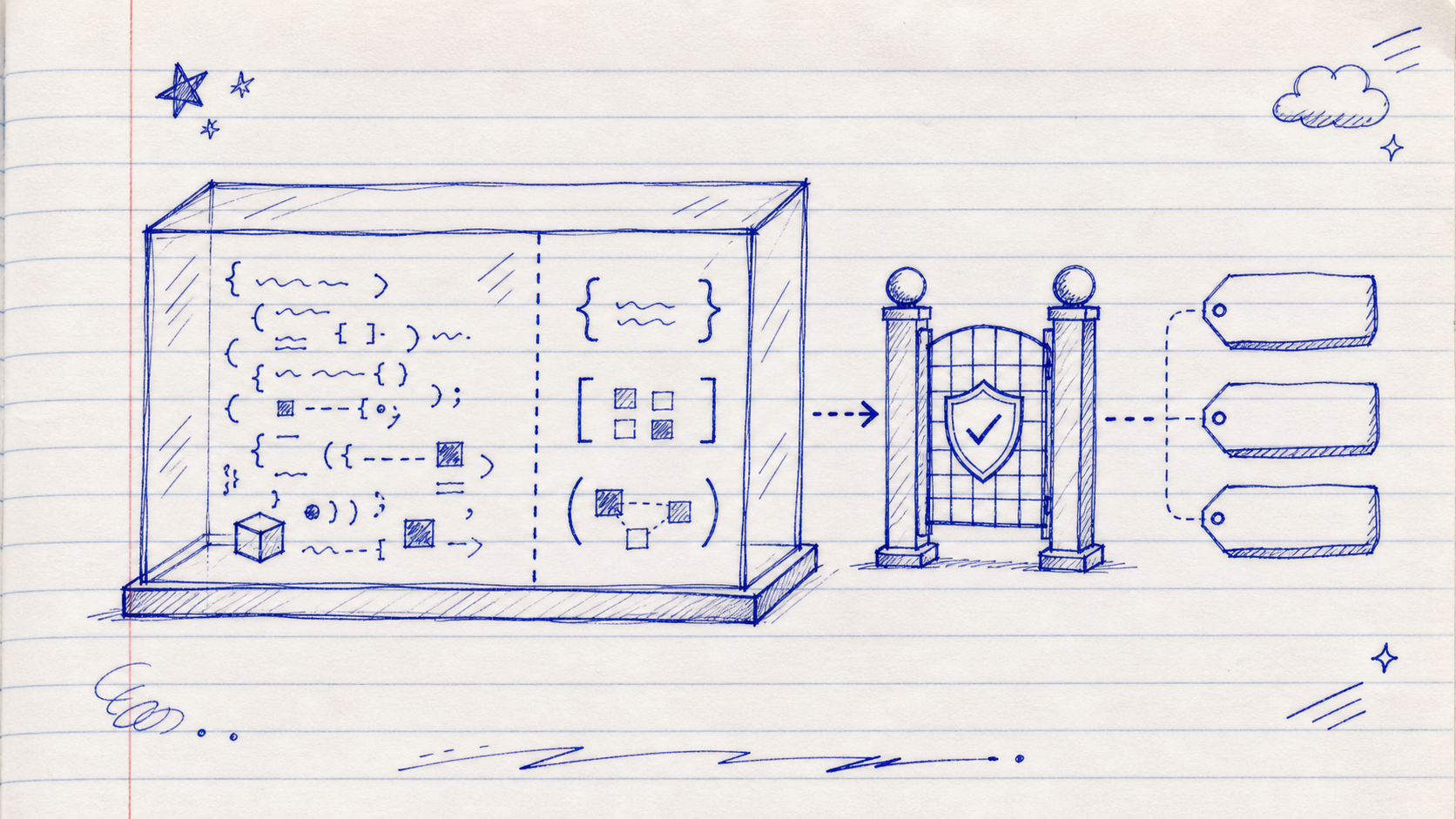
An toàn — sandbox không quyết quyền
Dĩ nhiên, để AI viết code rồi chạy nghe có vẻ dễ mời rủi ro nếu làm hời hợt. VibeWork không xem sandbox như một chi tiết trang trí. Mỗi lần execute tạo một sandbox mới, không dùng lại runtime, không cho trạng thái lần trước sống tiếp. Sandbox cũng bị tước các khả năng không cần: không fetch, không require, không filesystem, không process. Nó chỉ có những function được cài vào một cách có kiểm soát.
Bên ngoài sandbox còn có giới hạn thời gian chạy, giới hạn số lần gọi function, giới hạn kích thước script và validation theo schema. Những lớp này giúp tránh vòng lặp vô hạn, payload quá lớn hoặc input sai hình dạng. Nhưng điểm quan trọng nhất vẫn là authorization. Sandbox không tự quyết định ai được xem gì. Service layer của VibeWork vẫn là nơi kiểm tra user, tenant, scope và permission. Khi agent gọi vibework.list_tasks, function đó vẫn đi qua cùng tầng service như người dùng thật.
Điều này giữ cho Code Mode không trở thành một permission layer thứ hai, thứ về sau dễ lệch khỏi hệ thống chính. Nếu người dùng không được xem lương, sandbox không có phép màu để xem lương. Nếu scope hiện tại chỉ thuộc một tenant, function gọi ra cũng chỉ hoạt động trong tenant đó. AI không được cấp quyền nhiều hơn người đang dùng nó; nó chỉ có một cách linh hoạt hơn để thao tác trong phạm vi quyền đã có.
Bài học: expose khả năng lập trình, không phải hành động
Bài học lớn hơn là Code Mode không chỉ là một trick tiết kiệm token. Nó đổi cách nghĩ về thiết kế cho AI. Cách cũ nói: với mỗi thứ AI có thể làm, mình tạo một tool. Cách mới nói: mình đưa cho AI một API surface có type, có thể tìm kiếm, rồi để nó compose workflow bằng code. Ở mức tính năng, hai cách có thể cùng tạo được note follow-up. Ở mức thiết kế, một bên là danh sách nút bấm, bên kia là một ngôn ngữ thao tác.
Với internal tools, khác biệt này đáng kể. Công việc công ty hiếm khi là một hành động đơn. Nó thường là kéo dữ liệu từ vài nơi, lọc theo điều kiện, nhóm lại, kiểm tra ngoại lệ, tạo follow-up, rồi trả về một bản tóm tắt có thể hành động. Đó là logic. Logic thường rõ hơn khi được viết thành code so với bị bẻ thành nhiều lần bấm tool. Nếu harness có thể cho AI viết code an toàn, mình đang để model làm việc gần với khả năng tự nhiên hơn của nó.
Điều VibeWork xây không phải “thêm một MCP server nữa cho vui”. Nó gần như hướng ngược lại: ít tool hơn, ít thứ agent phải đọc hơn, ít vòng gọi hơn, và ít cơ hội bị lạc trong một menu quá lớn. Khi cần deploy (triển khai) thêm function mới vào hệ thống, registry lớn lên phía sau, còn giao diện dành cho agent vẫn gọn. Ngay cả trong workflow headless (chạy không cần giao diện người dùng), nguyên tắc vẫn giống nhau: bề mặt nhỏ, quyền rõ, logic nằm trong code ngắn có thể kiểm soát.
Nếu đang xây internal tool cho AI, câu hỏi nên đến sớm hơn phần danh sách tool. Mình có thật sự cần phơi ra 100 tool, hay cần một API surface nhỏ, có type, tìm được bằng search, và đủ an toàn để agent viết code trên đó?