Loop engineering: Từ thiết kế một AI agent đến thiết kế cái loop tự chạy nó
Một tầng đòn bẩy mới nằm ở hệ thống quyết định khi nào agent làm việc, với gate nào, giữ lại state gì — nhưng phần lớn dev vẫn chưa cần tới nó.
Chào bạn,
Bài trước mình có viết về việc thiết kế “linh hồn” cho một AI agent: đặt cho nó định danh, nguyên tắc, cách giao tiếp, quy trình làm việc, và một dạng trí nhớ để nó không phải bắt đầu lại từ con số không trong mỗi phiên. Nói gọn lại, lúc đó mình đang nói về cách biến một cuộc đối thoại với AI thành một hệ thống có cấu trúc.
Nhưng khi làm đủ lâu, Toàn bắt đầu thấy có một tầng khác nằm phía trên nữa.
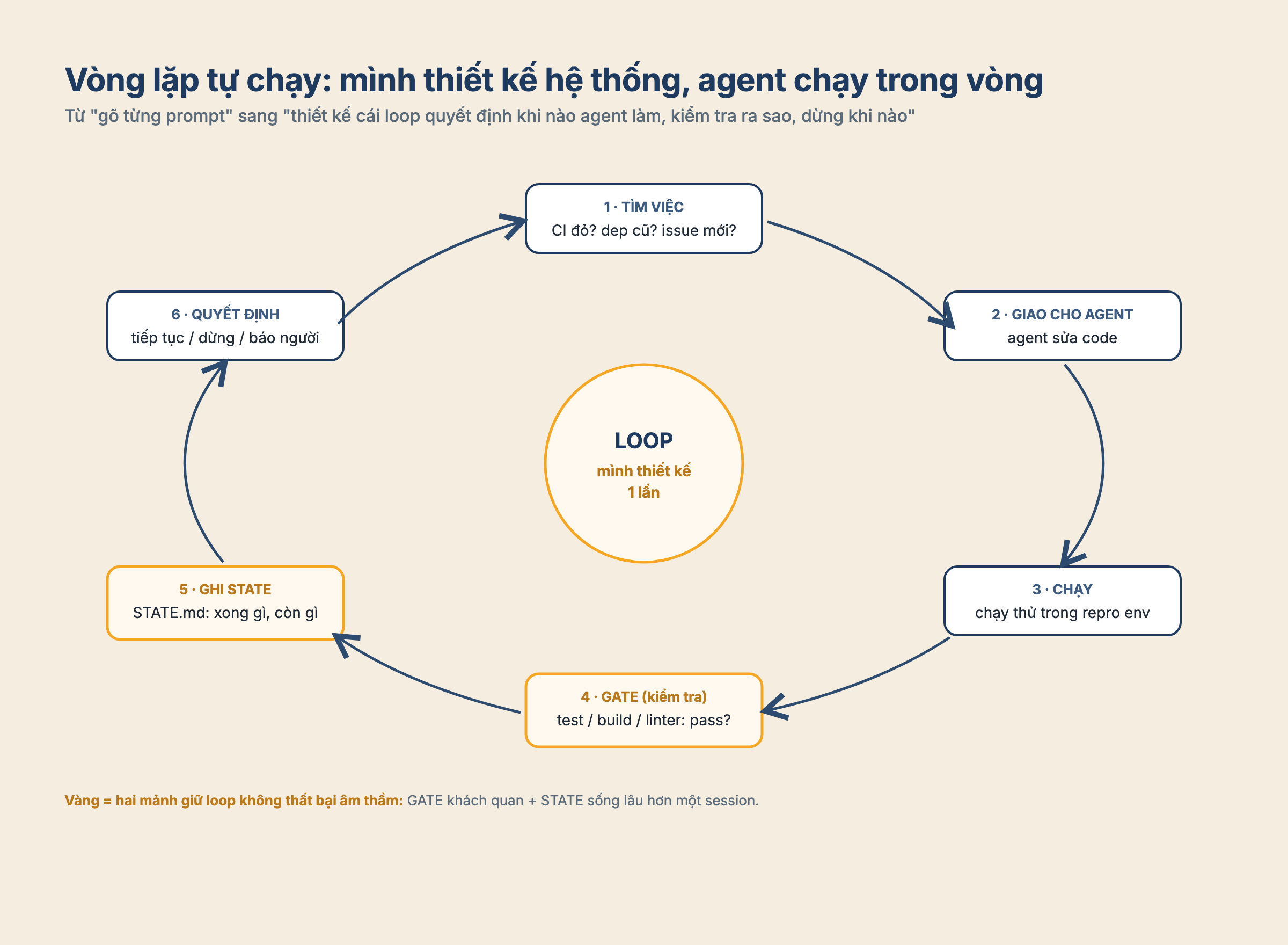
Nếu bài trước là chuyện thiết kế một agent có trí nhớ, thì bài này là chuyện thiết kế một loop tự chạy agent đó, mà không cần mình ngồi đó gõ prompt, chờ kết quả, đọc diff, rồi lại gõ tiếp. Đây là một thay đổi nhỏ về cách nhìn, nhưng khá lớn về cách làm việc. Điểm tạo đòn bẩy không còn nằm ở câu prompt mình viết, mà nằm ở cái hệ thống quyết định khi nào agent làm việc, làm việc gì, kiểm tra ra sao, ghi nhớ điều gì, và khi nào phải dừng.
Từ người viết prompt đến người thiết kế loop
Phần lớn developer hiện nay vẫn đang dùng coding agent theo kiểu rất thủ công. Mình mở terminal, gõ một prompt, chờ agent sửa code, đọc kết quả, thấy sai thì chỉnh prompt, rồi chạy lại. Agent lúc này giống như một công cụ mình cầm trên tay. Nó mạnh hơn cái búa rất nhiều, nhưng mình vẫn là người phải đứng đó cầm nó suốt.
Loop engineering bắt đầu từ một câu hỏi khác: nếu những bước đó cứ lặp đi lặp lại, tại sao mình không thiết kế luôn một cái loop để tự tìm việc, giao việc cho agent, kiểm tra kết quả, ghi lại trạng thái, rồi quyết định bước tiếp theo?
Khi mình tự dựng cái loop cho mình, với /loop, /auto, và một harness chạy dựa trên state file, cảm giác đầu tiên không phải là “AI làm hết việc cho mình”. Cảm giác đúng hơn là mình đang chuyển từ việc điều khiển từng câu sang thiết kế một đường ray. Agent vẫn là agent. Nó vẫn sai, vẫn lạc hướng, vẫn cần bị kiểm tra. Nhưng thay vì ngồi đẩy từng đoạn, mình thiết kế cái hệ thống để nó biết đi tiếp trong một phạm vi đã được rào lại.
Đó là điểm quan trọng. Loop không phải là phép màu. Loop chỉ là một cách đóng gói sự lặp lại.
Không phải việc gì cũng đáng đưa vào loop
Mình nghĩ đây là chỗ dễ bị nói quá nhất. Nghe “agent tự chạy” thì hấp dẫn thiệt, nhưng đa số developer chưa cần loop. Ít nhất là chưa cần ngay bây giờ.
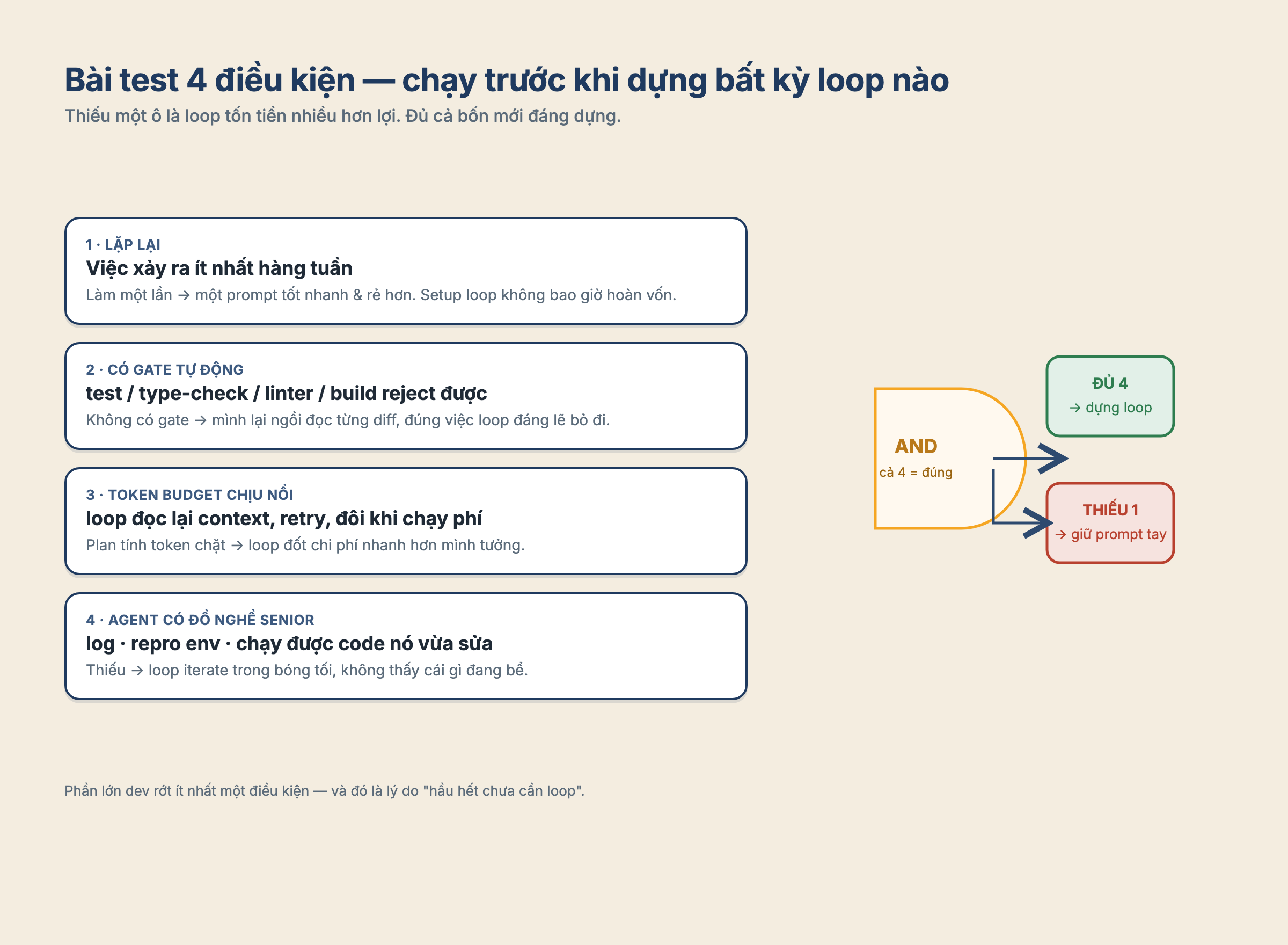
Một loop chỉ đáng công dựng khi nó qua được bốn câu hỏi rất thực tế:
- Việc đó có lặp lại đều đặn không, ít nhất là hàng tuần?
- Có test, type-check, linter, build, hay một gate tự động nào đó có thể reject kết quả không?
- Token budget của mình có chịu nổi chuyện agent đọc lại context, thử sai, retry, và đôi khi chạy không ra gì không?
- Agent có đủ công cụ như một senior engineer không: log, môi trường reproduce, quyền chạy code, và khả năng thấy cái gì đang bể?
Thiếu một trong bốn điều này, loop rất dễ trở thành một cách tốn tiền mà nhìn có vẻ thông minh.
Nếu công việc chỉ làm một lần, một prompt tốt thường nhanh hơn. Nếu không có automated verification, thì cuối cùng mình vẫn phải ngồi đọc từng diff. Nếu đang dùng một plan tính token chặt, loop có thể đốt chi phí nhanh hơn mình tưởng. Và nếu agent không thể chạy code nó vừa sửa, không đọc được log, không thấy được lỗi, thì nó đang iterate trong bóng tối. Nói cách khác, loop chỉ có ý nghĩa khi công việc vừa lặp lại, vừa có cách kiểm tra khách quan.
Những loop đầu tiên nên rất nhỏ
Mình thích cách nghĩ này: loop đầu tiên không nên là một đội quân agent. Nó nên là một cái máy nhỏ, làm một việc chán nhưng rõ.
Ví dụ tốt là CI failure triage. CI đỏ, loop đọc log, xác định nhóm lỗi, thử sửa, chạy test lại, rồi tạo một PR draft hoặc ghi lại kết quả. Dependency bump cũng vậy: mở PR, chạy build, chạy test, ghi chú breaking change nếu có. Lint-and-fix pass cũng là một ứng viên đẹp, vì linter trả về đúng hoặc sai rất rõ. Flaky-test reproduction cũng hợp, miễn là mình có cách chạy lại và ghi nhận kết quả. Những việc này không sexy, nhưng chúng có một đặc điểm rất quý: gate rõ ràng.
Ngược lại, những việc như rewrite architecture, sửa auth/payments, production deploy, hoặc biến một yêu cầu sản phẩm mơ hồ thành code chạy được thì không nên là loop đầu tiên. Không phải vì agent không giúp được — nó giúp được nhiều. Nhưng “xong” trong những việc đó là một judgment call, không phải một exit code. Khi “xong” cần kinh nghiệm của con người, mình nên ngồi ở ghế lái.
Một loop tốt bắt đầu bằng một lần chạy thủ công đáng tin. Trước khi schedule nó, mình phải tự chạy được một flow bằng tay: prompt ổn, context đủ, gate rõ, output đọc được. Sau đó mới biến flow đó thành skill. Rồi mới wrap nó trong loop. Cuối cùng mới cho nó chạy định kỳ. Thứ tự này nghe chậm, nhưng nếu nhảy thẳng tới automation, mình chỉ đang tự động hóa sự mơ hồ của chính mình.
Năm mảnh ghép làm loop bớt mong manh

Addy Osmani có một cách chia khá gọn về các phần của loop. Mình không muốn biến bài này thành tài liệu kỹ thuật, nhưng có vài mảnh ghép rất đáng nói, vì chúng làm cho loop bớt giống một cuộc thử vận may.
Mảnh đầu tiên là automation, nhịp tim của loop. Nó có thể chạy theo lịch, theo event, theo CI, hoặc theo một trigger mình đặt ra. Nhưng có một khác biệt quan trọng: một loop kiểu cadence như /loop sẽ chạy lại theo nhịp, dù trạng thái hiện tại là gì. Còn một loop kiểu goal-driven chỉ tiếp tục cho tới khi một điều kiện đã viết sẵn là đúng. Cái sau cần một verifier riêng để kiểm tra điều kiện dừng, vì agent vừa viết code không nên là người tự chấm bài của mình.
Mảnh thứ hai là worktree. Khi chỉ có một agent, mọi thứ còn đơn giản. Nhưng nếu có nhiều agent cùng sửa repo, file sẽ đụng nhau rất nhanh. Git worktree cho mỗi agent một working directory riêng, trên một branch riêng, nhưng vẫn chia sẻ lịch sử repo. Nó không giải quyết chuyện review, nhưng nó giảm bớt hỗn loạn khi chạy song song. Dù vậy, mình vẫn là cái trần cuối cùng: nếu mình chỉ review nổi hai PR một ngày, thì chạy mười agent song song không tự nhiên biến thành mười thay đổi được merge.
Mảnh thứ ba là skill, và đây chính là chỗ nối lại với bài trước. Skill là nơi mình viết kiến thức dự án một lần để agent đọc lại trong mỗi lần chạy: cách build, convention, những điều không nên làm, những quyết định từng gây đau. Không có skill, loop phải tự suy luận lại context từ đầu mỗi cycle. Có skill, intent của mình bắt đầu tích lũy.
Mảnh thứ tư là connector qua MCP. Đây là lúc loop chạm được vào công cụ thật: GitHub, Linear, Jira, Slack, Sentry, staging API, database đọc được. Khác biệt rất lớn nằm ở đây. Một agent không có connector chỉ có thể nói “đây là fix”. Một loop có connector có thể đọc issue, sửa code, mở PR, link ticket, rồi báo vào channel khi CI xanh. Tất nhiên, quyền càng rộng thì trách nhiệm càng lớn. Nhưng nếu làm đúng, đây là nơi loop bắt đầu có ích trong workflow thật.
Mảnh thứ năm là sub-agent. Nghe có vẻ phức tạp, nhưng nguyên tắc rất đời thường: đừng để người làm cũng là người tự chấm. Osmani có nói đại ý rằng model vừa viết code thường quá dễ tính khi chấm bài của chính nó. Anthropic cũng từng mô tả pattern evaluator-optimizer trong một bài kỹ thuật từ tháng 12/2024. Tên gọi có thể mới nổi lại, nhưng ý tưởng không mới: tách maker khỏi checker. Agent viết một thứ, verifier hoặc sub-agent khác kiểm tra nó bằng tiêu chí riêng. Cái verifier mà mình tin được mới là lý do mình dám rời ghế.
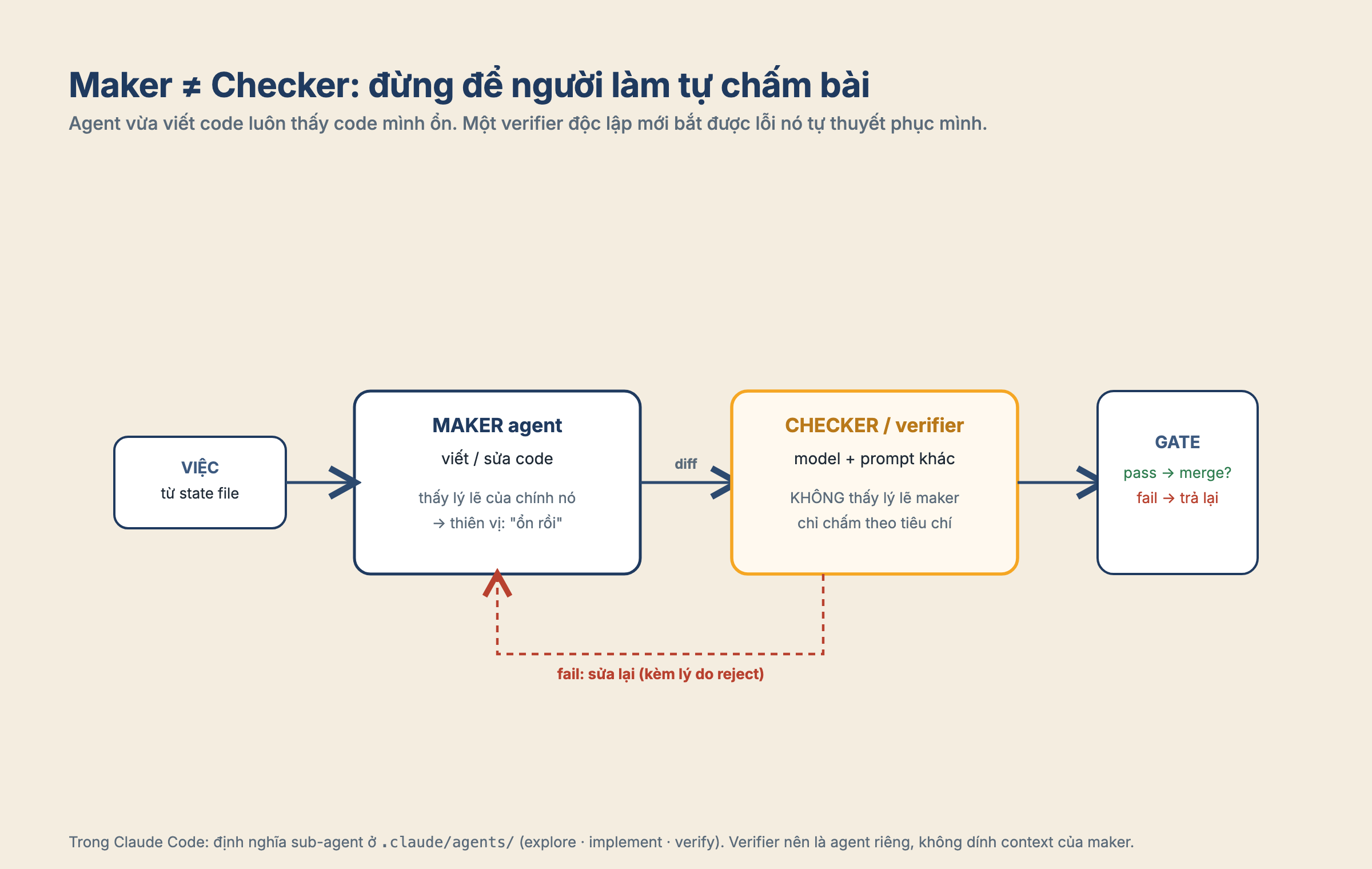
Trong Claude Code, mình định nghĩa mấy sub-agent này ở .claude/agents/ — mỗi cái một file, một vai trò. Cách chia mình hay dùng là ba vai: một agent explore đọc và hiểu, một agent implement viết code, một agent verify chấm lại theo spec. Điểm quan trọng là agent verify không nên dùng chung context với agent implement — nó phải nhìn kết quả bằng con mắt lạ, mới bắt được chỗ maker đã tự thuyết phục mình là đúng.
State file là xương sống của loop
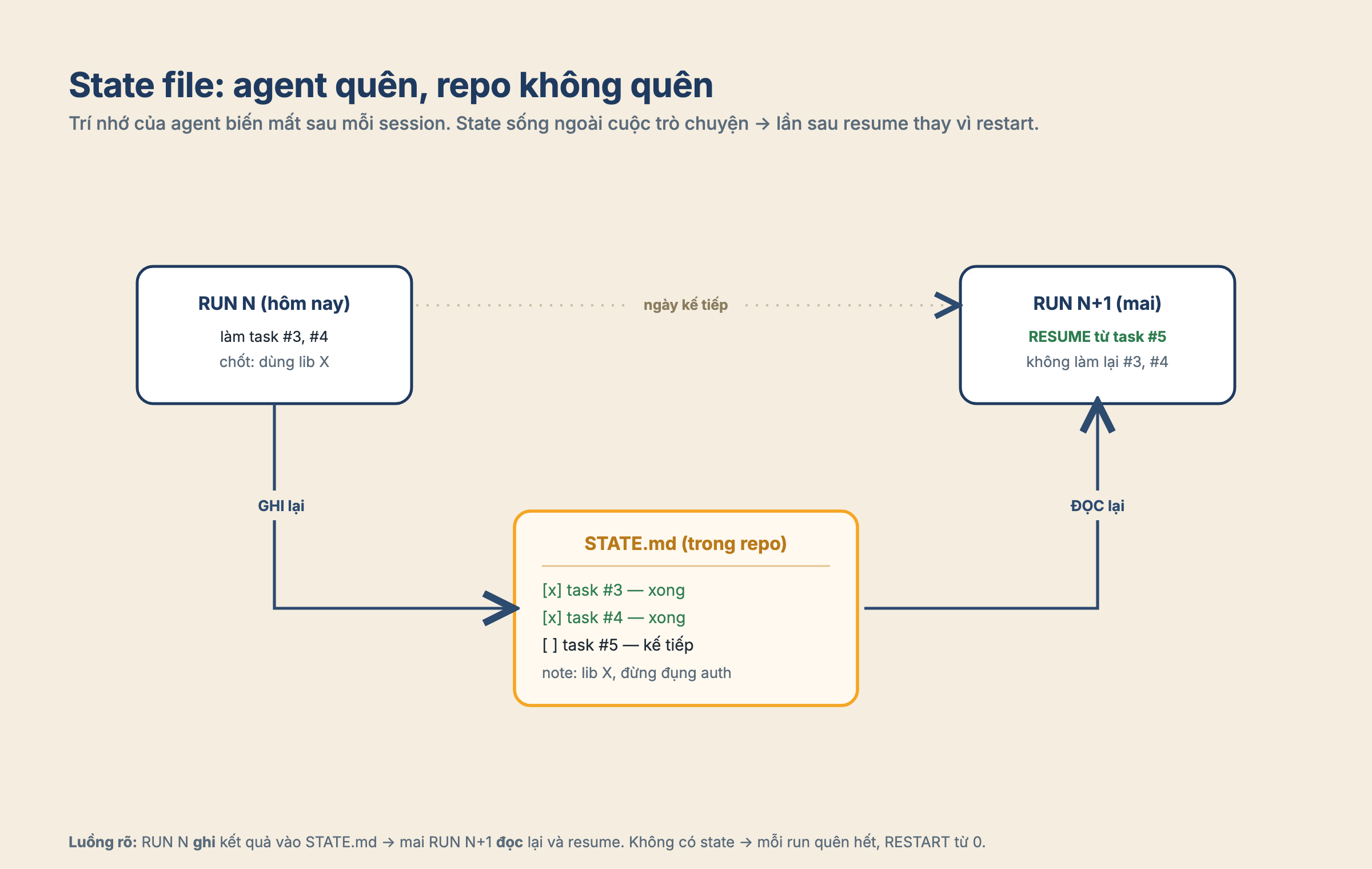
Nếu chỉ chọn một thứ để làm cho nghiêm túc, mình sẽ chọn state file.
Agent có trí nhớ ngắn. Những gì nó “hiểu” trong session hôm nay có thể biến mất ở lần chạy ngày mai. Repo thì không quên. Vì vậy, một loop cần một nơi nằm ngoài cuộc trò chuyện để ghi lại: đã làm gì, còn gì, quyết định nào đã chốt, lỗi nào đã gặp, lần sau nên tiếp tục từ đâu.
State file có thể rất đơn giản. Một file markdown trong repo, versioned, diff được, đủ tốt cho cá nhân hoặc team nhỏ. Với team lớn hơn, state có thể nằm ở Linear, GitHub Issues, hoặc một database. Hình thức không quan trọng bằng nguyên tắc: trạng thái phải sống lâu hơn một session. Một STATE.md thường nhìn đơn giản cỡ vầy, và chính sự đơn giản đó là lý do nó hoạt động:
# STATE — loop dọn lint cho repo X
## Đã xong
- [x] task #3 — fix lint trong /api (PR #214, đã merge)
- [x] task #4 — bump eslint 8 → 9 (PR #216, đã merge)
## Kế tiếp
- [ ] task #5 — sửa 12 warning trong /web
## Ghi nhớ (đừng quên giữa các run)
- Dùng lib X cho date, KHÔNG đụng auth flow
- Mỗi run mở tối đa 1 PR, chờ CI xanh rồi mới qua task sauĐầu mỗi run, loop đọc file này trước tiên: thấy task #3, #4 đã xong thì bỏ qua, nhảy thẳng vào task #5. Cuối run, nó ghi lại kết quả vào đúng file đó. Nhờ vậy mai chạy lại, nó resume chứ không làm lại từ đầu.
Mình hay nghĩ thế này: state file trả lời câu “đang ở đâu?”, còn một file kiểu VISION.md trả lời câu “đang đi về đâu?”. Với những loop dài, hai thứ này nên đi cùng nhau. Nếu không, agent rất dễ drift. Những ràng buộc ban đầu như “đừng đổi public API” hay “không đụng auth flow” có thể mờ dần sau nhiều vòng lặp. Bắt loop đọc lại high-level spec ở mỗi run là một cách kéo nó về đúng hướng. Câu mình tự nhắc mình là: agent quên, repo không quên.
Gate phải cứng, không phải lời hứa mềm
Một loop không có gate cứng là một loop đang tự tin quá mức.
Gate tốt là thứ trả về pass hoặc fail: test xanh hay đỏ, build compile hay không, linter zero hay non-zero, type-check qua hay không. Những gate này không cần cảm xúc. Nó không nói “có vẻ ổn”. Nó chỉ cho biết có qua điều kiện tối thiểu hay không.
Geoffrey Huntley có nhắc tới một kiểu lỗi gọi vui là Ralph Wiggum loop: agent đáng lẽ chỉ emit completion token khi xong, nhưng lại emit quá sớm, thế là loop thoát ra với một việc làm nửa chừng. Đây là dạng lỗi nguy hiểm, vì nó thất bại rất yên lặng. Nhìn log có thể thấy “done”, nhưng repo thì chưa thật sự xong.
Cách tránh không phải là viết prompt dài hơn để agent “nhớ làm cho xong”. Cách tránh là gate khách quan hơn, hard stop rõ hơn, verifier độc lập hơn. Loop phải có giới hạn token, số iteration, hoặc thời gian chạy. Nếu không, nó có thể tiếp tục tiêu tiền cho tới khi một người nào đó nhìn hóa đơn. Một loop trưởng thành không phải loop chạy mãi. Nó là loop biết khi nào phải dừng.
Cái giá không chỉ nằm ở token
Token cost dễ thấy, vì nó hiện trên bill. Nhưng có một loại chi phí âm thầm hơn: comprehension debt.
Khi loop ship code nhanh hơn tốc độ mình đọc hiểu code, khoảng cách giữa repo và đầu óc của team bắt đầu rộng ra. Ban đầu chuyện đó có vẻ không sao. Test vẫn xanh, PR vẫn merge, velocity nhìn rất đẹp. Nhưng một ngày nào đó production có lỗi, và không ai thật sự hiểu hệ thống đang vận hành bằng những assumption nào. Lúc đó cái bill đau nhất không phải token.
Còn một thứ nữa mình gọi là cognitive surrender: cảm giác muốn thôi không hình thành ý kiến riêng nữa, chỉ accept những gì loop trả về vì nó nhìn có vẻ hợp lý. Đây là cái bẫy rất dễ rơi vào khi agent viết nhanh, giải thích trôi chảy, và diff thì dài. Mình bắt đầu review bằng cảm giác “chắc nó biết nó đang làm gì”.
Nhưng loop không miễn trừ trách nhiệm kỹ sư. Nó chỉ đổi hình dạng trách nhiệm đó. Mình vẫn phải đọc diff, spot-check gate, giới hạn phạm vi, và không cho loop tự quyết những việc thuộc về kiến trúc hay rủi ro cao. Build the loop, nhưng stay the engineer.
Một loop không được review là một attack surface
Khi một hệ thống có thể tự đọc issue, sửa code, mở PR, chạy tool, và post kết quả, nó cũng trở thành một bề mặt tấn công. Đây không còn là chuyện “AI có viết code bug không?” nữa. Đây là chuyện quyền truy cập, log, credential, skill, connector, và cả supply chain.
Generated code không nên được merge hoặc deploy mà không có một human gate, nhất là với dependency change, auth, payment, hay bất cứ thứ gì irreversible. Gate cũng nên bao gồm SAST, dependency audit, secret scanning, và những kiểm tra cơ bản về permission. Skill cũng không phải vùng an toàn tuyệt đối. Có báo cáo audit nhắc tới 520 trên 17.022 skill bị rò credential, nên mình không xem skill như một file hướng dẫn vô hại.
Credential lọt vào log là một lỗi rất thường bị xem nhẹ. Permission scope cũng vậy. Một connector ban đầu chỉ cần đọc issue, nhưng sau vài lần mở rộng có thể có quyền ghi, quyền deploy, quyền post ra ngoài. Với loop chạy không có người ngồi cạnh, mình nghĩ nên re-audit quyền định kỳ, ví dụ mỗi 30 ngày, và luôn hỏi: quyền này có còn cần không? Automation tốt là automation bị giới hạn đúng mức.
Dựng thử một loop, từ đầu đến cuối
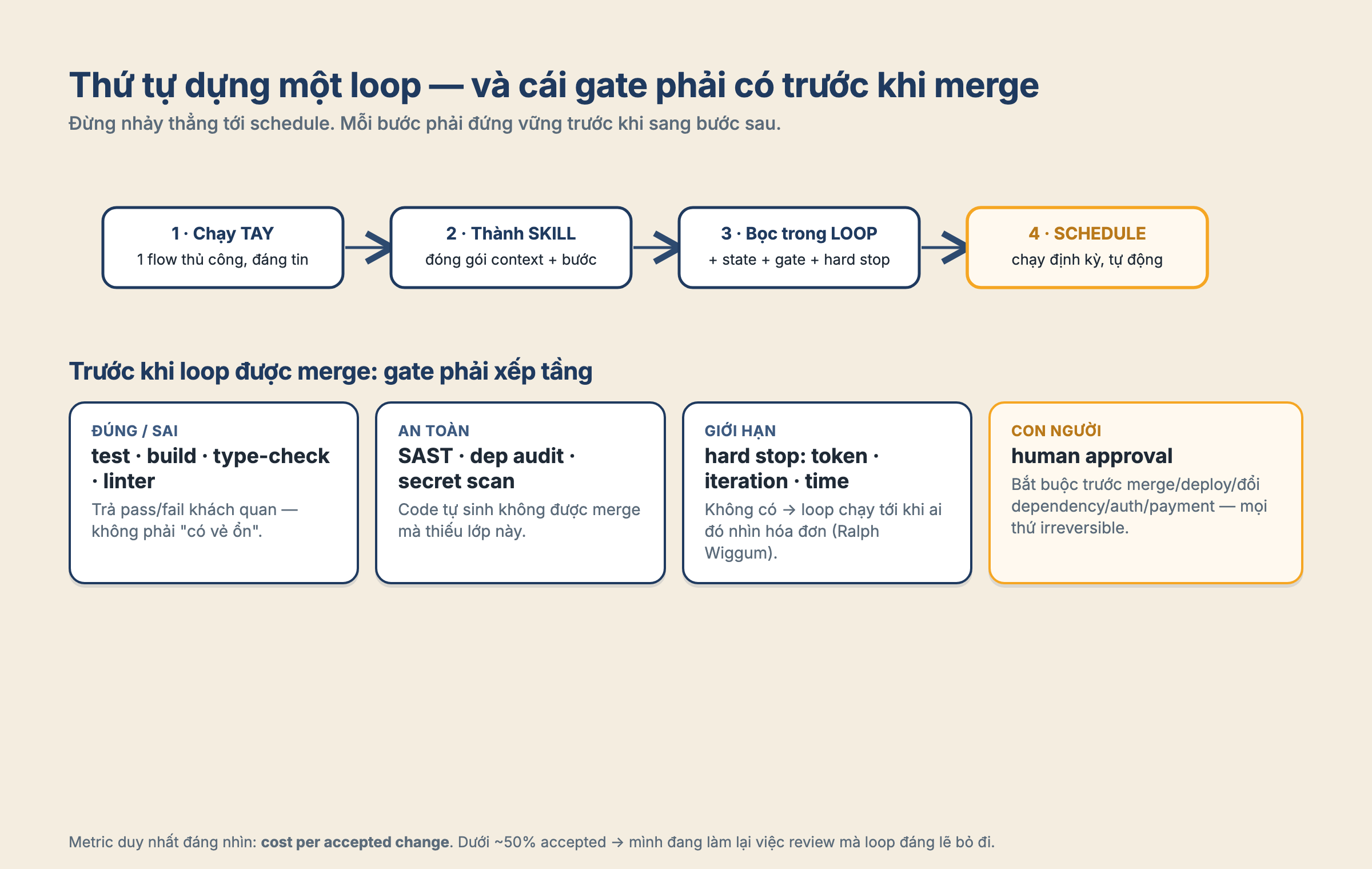
Giả sử mình muốn dựng một loop nhỏ để dọn lint warning trong /web. Mình chọn ví dụ này vì gate của nó rõ: chạy npm run lint, nếu exit code zero thì qua, non-zero thì chưa qua. Một loop kiểu này nhìn sẽ như vầy: ban đầu mình làm bằng tay, rồi đóng gói thành skill, rồi mới bọc thành loop có state và verifier, cuối cùng mới schedule cho nó chạy định kỳ.
Bước đầu tiên mình sẽ chạy tay một lần cho đáng tin. Mình mở agent, ví dụ Claude Code, rồi giao đúng một việc: “đọc output của linter, sửa các warning trong thư mục /web, đừng đụng gì ngoài đó”. Sau đó mình ngồi coi nó làm có đúng ranh giới không, prompt có mơ hồ chỗ nào không, và quan trọng nhất là gate npm run lint có thiệt sự bắt được lỗi mình quan tâm không. Nếu một lần chạy tay mà mình còn chưa tin được, ví dụ agent sửa lan qua auth flow, hoặc linter vẫn xanh dù warning còn đó, thì lúc này chưa có gì đáng để tự động hóa hết.
Khi lần chạy tay đã đủ ổn, mình mới đóng gói nó thành một SKILL.md trong .claude/skills/. Trong file đó mình ghi lại việc cần làm, cách chạy linter, convention của repo, vùng được phép sửa, vùng không được đụng tới. Ví dụ có thể ghi rõ “chỉ sửa trong /web”, “không đổi auth flow”, “không refactor component nếu chỉ cần sửa import order”. Cái lợi của skill không phải là nó làm agent thông minh hơn một cách thần kỳ, mà là lần sau agent không cần nghe mình kể lại từ đầu trong một prompt dài và dễ sót.
Sau đó mình mới bọc nó trong loop. Loop cần một state file, ví dụ STATE.md, để mỗi vòng biết nó đang ở đâu, đã thử gì, còn lỗi gì, và nếu bị ngắt thì resume được thay vì đoán lại. Mình cũng đặt hard stop, như giới hạn iteration hoặc token, để nó không chạy mãi trong một góc kẹt. Phần chấm điểm nên để một verifier riêng làm, thường là chạy lại npm run lint và đọc kết quả, thay vì để chính agent tự tuyên bố “xong rồi”. Trong Claude Code có thể dùng /loop để chạy theo nhịp, hoặc một dạng goal-driven chạy tới khi điều kiện “linter xanh” đúng.
Cuối cùng mới tới schedule. Sau vài lần chạy tay hoặc bán tự động đã đáng tin, mình mới cho loop chạy theo lịch, hoặc trigger khi CI đỏ vì lint. Kết quả nó tìm được nên rơi vào một chỗ để mình review, như một branch, một PR, hoặc một report, chứ không tự merge thẳng. Điểm ăn tiền của cả chuyện này nằm ở chỗ mình hiểu việc trước khi giao nó đi. Thứ tự chậm chậm đó chính là cái bảo vệ mình khỏi tự động hóa sự mơ hồ.
Vậy cuối cùng ai nên làm loop?
Nếu team của bạn có nhiều việc lặp lại, có test suite mạnh, có CI rõ, có budget, và có review capacity, loop engineering rất đáng thử. Những nơi như CI triage, dependency bump, lint fix, flaky test, issue-to-PR draft trên codebase được test tốt là vùng đất khá hợp.
Nếu bạn là solo builder đang dùng consumer plan, code chưa có automated verification, hoặc bottleneck thật sự nằm ở review chứ không phải typing speed, thì có thể chưa cần. Một prompt tốt, một agent có skill tốt, và một state file gọn nhiều khi đã đủ tạo ra rất nhiều leverage rồi.
Điều mình muốn giữ lại là sự tỉnh táo. Loop engineering là thật. Nó không phải hype rỗng. Nhưng nó cũng không phải thứ mọi dev cần lao vào ngay. Nó chỉ đáng làm khi mình có đủ điều kiện để loop tự chạy mà vẫn bị kiểm soát bởi gate, state, và review.
Nếu pass được bài test đó, hãy bắt đầu nhỏ: một automation, một skill, một state file, một gate. Chạy tay cho ổn. Viết lại thành skill. Bọc nó trong loop. Rồi mới schedule. Thứ tự này quan trọng hơn mình tưởng, vì nó buộc mình hiểu việc mình đang tự động hóa trước khi trao nó cho agent chạy một mình.
Bài trước, mình nói về chuyện thiết kế một agent có trí nhớ để cuộc đối thoại với AI bớt rời rạc. Bài này, mình muốn đi thêm một tầng: thiết kế cái loop để agent đó có thể làm việc khi mình không ngồi đó. Nhưng cái đích không phải là biến mình thành người đứng ngoài. Cái đích là để mình đứng đúng chỗ hơn — thiết kế hệ thống, đặt giới hạn, kiểm tra kết quả, và giữ lấy trách nhiệm kỹ sư.
Bạn có công việc lặp lại nào trong repo của mình mà nếu có một loop nhỏ, gate rõ, nó sẽ thật sự tiết kiệm thời gian cho bạn không? Mình rất muốn nghe bạn kể.
Thân mến,
Toàn